We have
your content
covered
Automatically detect when your content is aired on TV or radio broadcasts.
Automatically detect when your content is aired on TV or radio broadcasts.
Get advanced insights by tracking
your content across channels,
markets, networks, and more.
Get advanced insights by tracking your content across
channels, markets, networks, and more.
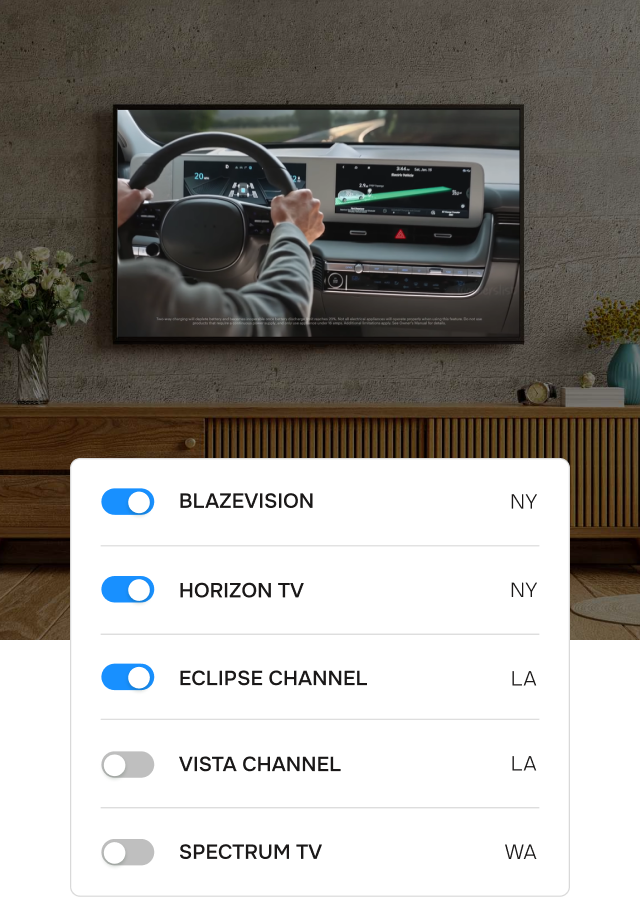
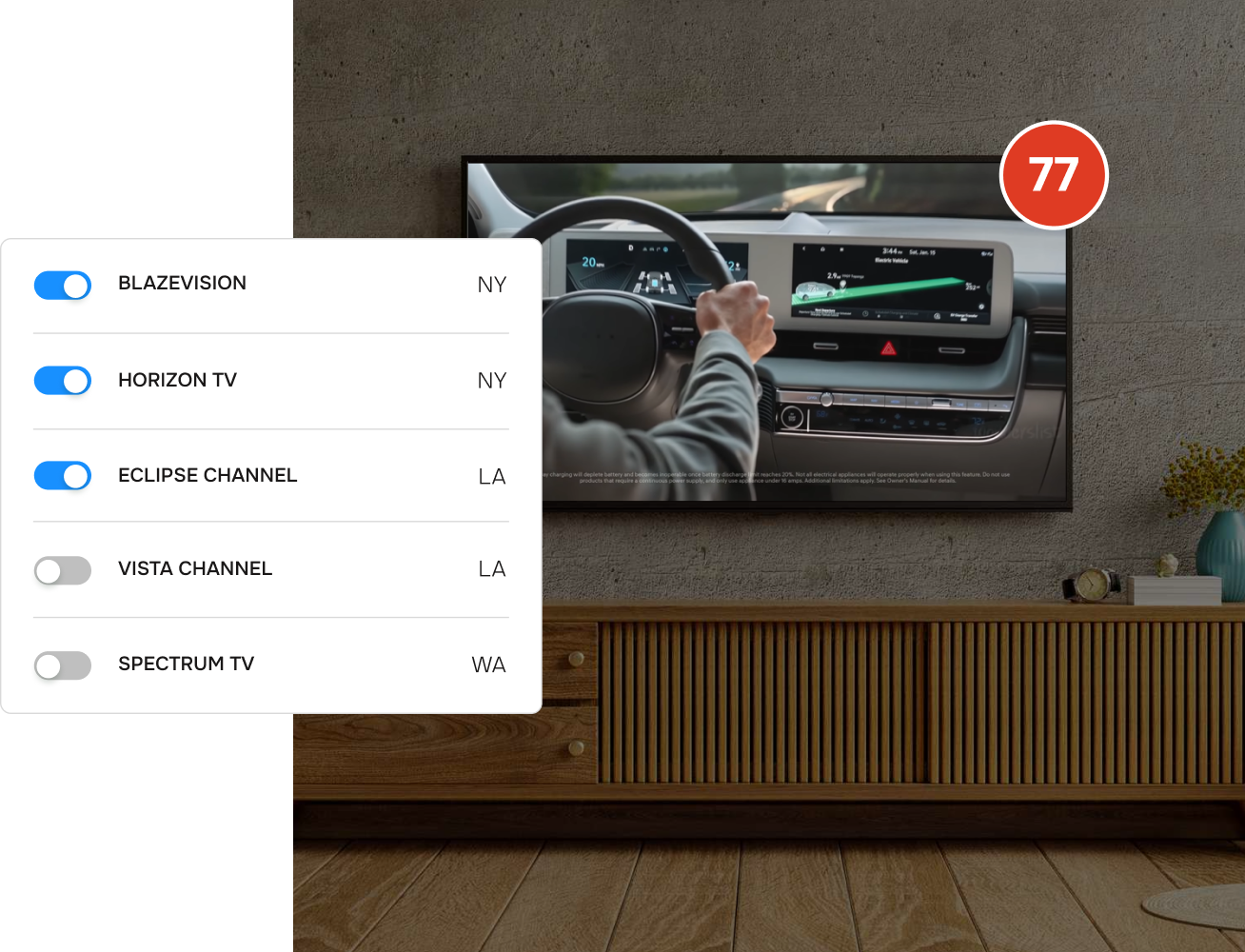
Track your content airing, whether it’s on a local station or national network like NBC, CBS, ABC, etc. Select from more than 1,100 US TV channels both regional and national. Get near-real-time results.
Learn MoreNavigate the advertising landscape with Emysound's extensive catalog. Each day, our system detects and tags over 300 advertisements in real-time, providing you with a wealth of information at your fingertips
Learn MoreMissed something? Rewind the recent past with Emysound's powerful retrospective search. Covering over 300 channels, you have the archival mastery to delve into the last 48 hours of broadcast content.
Learn MoreUS linear TV AD spending
Viewers age 16 to 24 report searching for a product online after seeing a television ad
Ensure that the broadcast partners you work with are in compliance with your licensing agreements.
Monitor competitors, stay on top of industry trends, and see how your marketing investments are performing with a single platform.
Emy stores the last 48 hours of content that has been broadcasted on TV channels around the US.
You can run historical searches identifying which TV channels aired your content in the past.
Pay as you go.
Billed at the end of the month for daily usage.

Upload content you want to monitor via the Emysound dashboard.
Select TV channels you want to monitor from the list.
Craft reports, preview matches, or integrate with Emysound API.
We offer a free Community Edition for non-commercial projects.
Our API offers rich third-party integration opportunities.
Emysound community edition is completely free and available to all for non-commercial use (non-profit). It's built with developers in mind and we're committed to opensource collaboration.
Learn MoreOur Emy platform is built specifically for the needs of the developer by providing them with an easy way to get started without worrying about configuration or setup headaches while still having full control over their data and privacy.
Learn More